AMD FX-8150: Bulldozerista Zambeziin ja FX:n
Artikkelin kirjoittaja: Teemu Laitila | 0 kommenttia
Yksi liukulukuyksikkö, AVX-suorituskyky ja L2
Kaksi ydintä, yksi FPU
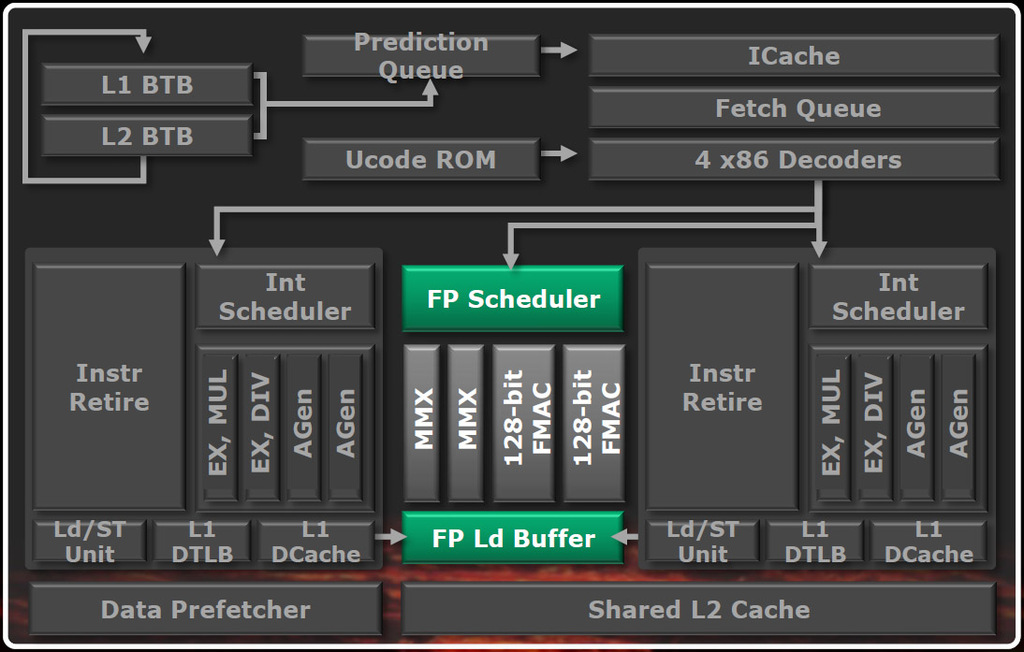
Jaettu liukulukuyksikkö toimii erillään kokonaislukuhihnasta. Kun operaatiot dekoodauksen jälkeen lähetetään eteenpäin, kaikki liukulukuoperaatiot ohjataan liukulukuajastimelle. Liukulukuajastimella käskyt joutuvat kilpailemaan resursseista ja kaistasta riippumatta siitä mihin säikeeseen ne kuuluvat.
Kuten alla olevasta diagrammista näkyy, AMD:n liukulukujen laskentaan käytettävä logiikka on erilainen kuin kokonaislukujen. Sen tarkoituksena on pelkästään suorittaa käskyjä ja se ilmoittaa operaatioiden valmistumisesta alkuperäistä operaatiota hoitaneelle kokonaislukuyksikölle, joka puolestaan hoitaa käskyjen loppuunkäsittelyn.
Liukulukuyksikkö sisältää kaksi MMX-liukuhihnaa ja kaksi 128-bittistä FMAC-yksikköä (Fuse multiply-accumulate). FMAC-liukuhihnat tukevat neljää operandia, jotka antavat arvot säilyttävän tuloksen. Intel aikoo ottaa kolmen operandin formaatin käyttöön tulevassa Haswell-mikroarkkitehtuurissaan (joka tulee Ivy Bridgen jälkeen). AMD:kin aikoo tukea FMA3:a Bulldozeria seuraavassa Piledriver-arkkitehtuurissa vuonna 2012.
Aina kun prosessorivalmistajien tiet eroavat toisistaan, herää kysymys miten se vaikuttaa sovelluskehittäjiin. Tiedustelimme siis SiSoftwaren Adrian Silasilta, millaisia seuraamuksia hän odottaa valmistajien suunnitelmista. Silasin mukaan suuri osa kehittäjistä ei haluaisi toteuttaa kolmea eri koodipolkua (yksi vain AVX:lle, toinen AVX:lle ja FMA3:lle ja kolmas AVX:lle ja FMA4:lle.) Siinä on tosiaan järkeä. Kun ottaa huomioon miten vähän nykyiset sovellukset hyödyntävät AVX-käskyjä ja miten käytännössä mikään niistä ei hyödynnä FMA:ta, AMD:n pitäisi olla paremmassa asemassa, kunhan Piledriver saapuu markkinoille.
Tämän päivän osalta tärkeämpi kysymys on kuitenkin kuinka Bulldozerin AVX-tuki pärjää Intelin vastaavaan? Sandy Bridge suorittaa kaksi 256-bittistä AVX-operaatiota jaksoa kohti, kun Bulldozer kykenee yhteen.
Ennen tätä julkaisua olin yhteydessä Noel Borthwickiin, joka on taitava muusikko ja Cakewalk-yhtiön teknologiapäällikkö. Puhuimme pääosin yhtiön työstä optimoida Sonar X1 -sovellus AVX-käskyjä varten. Noel oli mukana kirjoittamassa tutkimusta, jonka perusteella AVX-käskyillä voidaan vähentää sovelluksen aiheuttamaa kuormitusta kun äänen bittisyvyyden muutoksia suoritetaan samalla kun audiopuskureiden sisältöä ajetaan ulos, renderöidään sekä miksataan. Usein toistuvia konversioita ovat 24-bittinen kokonaisluku 32-bittiseksi liukuluvuksi, 64-bittinen double-precision-muutos sekä 32-bittinen liukuluku 64-bittiseksi double-precision-luvuksi.
Tähän liittyen Noel lähetti meille yhtiön kehittämien testiohjelmien binäärit, joiden avulla voidaan vertailla kahta Cakewalkin AVX-optimoitua rutiinia vastaavaan ei-optimoituun versioon. AMD:lla ja Intelillä on molemmilla pääsy tasan samoihin testityökaluihin, joten tulosten ei pitäisi olla yllätys kummallekaan.
|
Arkkitehtuuri |
Operaatio |
Tulos (Kellojaksoja voitolla/häviöllä) |
|---|---|---|
|
AMD Bulldozer |
Copy Int24toFloat64 |
61% hyöty |
|
AMD Bulldozer |
Copy Float32toFloat64 |
77% häviö |
|
Intel Sandy Bridge |
Copy Int24toFloat64 |
69% hyöty |
|
Intel Sandy Bridge |
Copy Float32toFloat64 |
14% hyöty |
"Copy Int24toFloat64" operaatiossa Intelin Core i7-2600K hyötyy AVX:stä 69 prosenttia kun AMD:n FX-8150 onnistuu saavuttamaan myöskin vaikuttavan 61 prosentin hyödyn. Mutta mitä "hyöty" tässä tapauksessa tarkoittaa? Käytännössä se kuvaa AVX:n käytöllä säästettyjen prosessorikierrosten määrää, eli se kasvattaa potentiaalista kaistanleveyttä. Toisella tapaa ilmaistuna Sandy Bridge vähentää käytettyjä kellojaksoja 1,69 kertaisesti ja Bulldozer 1,61 kertaisesti.
Toisaalta taas "Copy Float32toFloat64" operaatiossa Core i7-2600 hyötyy 14 prosenttia kun FX-8150 jää jopa 77 prosenttia häviölle. Tätä häviötä voidaan selittää sillä, että Cakewalkin vektorilaskutoimitukset (tai hieman epätodennäköisemmin Microsoftin) eivät ole optimoituja AMD:n arkkitehtuurille. Ongelma kuitenkin saattaisi korjaantua joko testisovellusten päiviytksellä tai Visual Studio -päivityksellä.
Jos tarkastellaan Sandra 2011 -testin tuloksia, havaitaan, että AVX-tuki parantaa FX-8150:n suorituskykyä sekä kokonaisluku- että liukulukuoperaatioissa. Sandy Bridge kuitenkin onnistuu saavuttamaan vielä suuremman hyödyn.
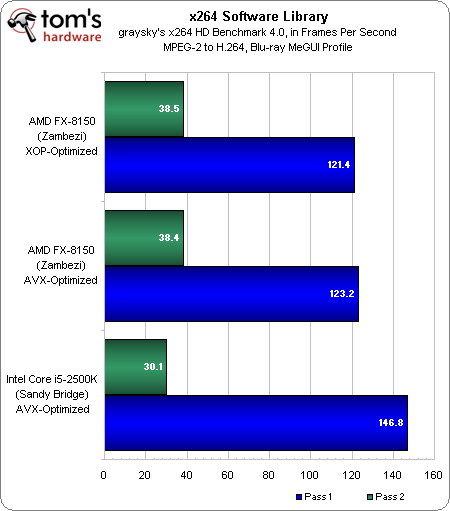
Juuri ennen kuin saimme kaikki testit valmiiksi, AMD lähetti meille kaksi eri versiota x264-kirjastosta, joka vastaa käytännön toimista eri sovellusten kuten HandBraken taustalla. AMD:n lähettämät versiot kuitenkin sisältävät tuen AVX- ja XOP-käskyille, joista jälkimmäinen on vain AMD:n arkkitehtuurin ominaisuus.
Muokkasin Tech ARP:n x264 HD Testi 4.0 -testiä käyttämään kumpaakin uusista versioista ja käytin CPU-Z 1.58:aa järjestelmän tietojen tarkistamiseen sekä ajoin testin FX-8150:llä sekä Intelin Core i5-2500K:lla.
Tulokset AMD:n AVX- ja XOP-koodipolkuja käyttäen ovat melko yhteneväisiä. Intel suorittaa ensimmäisen kierroksen nopeammin, mutta AMD on nopeampi toisella kierroksella.
Kannattaa muistaa, että AVX-optimoidut testit ovat vielä harvassa ja kestää kohtalaisen kauan, ennen kuin saamme kattavampia tuloksia siitä, miten AVX-käskyt vaikuttavat näihin arkkitehtuureihin.
L2-välimuistin jakaminen
Mainitsin jo aiemmin jaetun L2 TLB-muistin, joka on vastuussa käskyjen säilömisestä (etuosat) ja datapuolen (kokonaislukuytimet) pyynnöistä. Tämän lisäksi ytimet jakavat yhden yhdistetyn L2-välimuistin. Tämä tallennustila on 2 MB moduulia kohti, mikä tarkoittaa 8 MB L2-välimuistia neljän moduulin FX-8000-sarjan prosessorissa.

Kommentoi artikkelia
Kirjaudu sisään