AMD FX-8150: Bulldozerista Zambeziin ja FX:n
Artikkelin kirjoittaja: Teemu Laitila | 0 kommenttia
Jaetut etuosat ja kaksi kokonaislukuyksikköä
Etuosien jakaminen
Kuten jo aiemmin mainittiin, Bulldozerin käskynhaku ja dekoodausvaiheet ovat jaettu molempien ytimien kesken. AMD käyttää lomitettua monisäikeistystä kunkin käskyn säikeen tunnistamiseen, päättämään minkä säikeen työ on kiireisin ja suorittamaan operaation kyseisen säikeen puolesta. Se kykenee vaihtamaan toimintaansa jokaiselle jaksolle, jotta työ etenee molemmissa säikeissä.
AMD on itse asiassa päätynyt erottamaan hypyn kohteen ennakoinnin (branch target predictor) käskyjen noutamisesta, mikä mahdollistaa kohteen ennakoinnin jatkumisen huolimatta noutoputkessa tapahtuvista viivästyksistä. AMD mukaan erottaminen mahdollistaa vielä tärkeämmän toiminnon, joka on "Prediction-directed instruction prefetech", joka on erittäin kehittynyt käskyjen esihakija ja joka AMD:n mukaan kykenee erittäin suureen ennustustarkkuuteen ja on lisäksi energiatehokas.
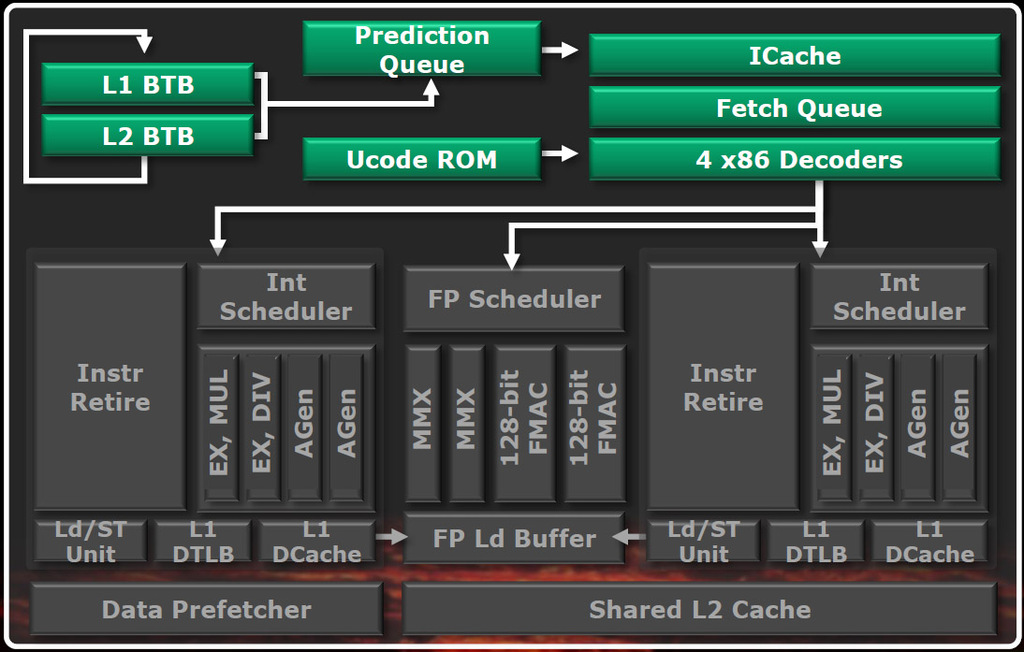
Hypyn ennakointia ohjaa 512-yksikköinen L1-muisti ja 5000-yksikköinen L2-muisti, jotka toimivat ennakoinnin apuna (branch target buffer, BTB). Tämä linjasto on vastuussa tulevien hakuosoitteiden ennustamisesta ja jonon pitämisestä mahdollisimman täytenä. Käytössä on itse asiassa kaksi jonoa eli yksi jono per säie, jonka avulla varmistetaan, että ytimille on koko ajan tekemistä. Käskyhaku hakee tulevia osoitteita jonosta.
Jonosta osoitteet päätyvät käskyhaun 64 KB kokoiseen kaksisuuntaiseen käskyvälimuistiin, joka jaetaan molempien säikeiden kesken (säikeet joutuvat kilpailemaan dynaamisesti muistiin pääsystä). Seuraavaksi Bulldozerin käskyjonon x86-käskyt syötetään dekoodausvaiheeseen, joka koostuu neljästä x86 dekooderista, jotka puolestaan siirtävät enimmillään neljä käskyä kellojaksoa kohti ajastimille (scheduler).
Kun tapahtuu niin kutsuttu huti, eli käskyä ei löydykään käskyvälimuistista, sitä haetaan ensiksi L2-välimuistista ja sen jälkeen järjestelmämuistista, jos tarpeen. Hutien aiheuttamat toimet kasvattavat latenssia merkittävästi. Siispä kun käskyä haetaan muualta, jonon muiden hakuosoitteiden osumista tarkistetaan sillä välin. Jos nekään eivät ole oikeita, L2-välimuistiin lähetetään uusi pyyntö kun ensimmäistä käskyä edelleen haetaan, jolloin käskyjen hakuun käytettyä kokonaisaikaa saadaan vähennettyä.
Kaksi kokonaislukuyksikköä
Prosessorin etuosista dekoodatut käskyt kulkevat kahdelle itsenäiselle kokonaislukuytimelle, jossa ne suoritetaan kokonaan out-of-order-periaatteella. Molemmat ytimet sisältävät kaksi suoritusyksikköä ja osoitteenluontiyksikköä.

Molemmat ytimet myös sisältävät oman 16 KB L1-välimuistin ja lisäksi molemmilla ytimillä on 32-yksikköinen L1 "Data translation lookaside buffer" eli TLB, jonka taustalla löytyy 1024-paikkainen kahdeksansuuntainen L2 TLB joka on sijoitettu ytimien jakamaan osuuteen. Kolmanneksi molemmilla ytimillä on out-of-order periaatteella toimiva lataus/tallennus yksiköt, jotka kykenevät suorittamaan joko kaksi 128-bittistä latausta jaksoa kohti tai yhden 128-bittisen tallennuksen per jakso.
Kommentoi artikkelia
Kirjaudu sisään